Instalar e configurar um cluster Apache Spark no Hadoop Ubuntu 18.04 (Multi-Node)
Neste artigo, fornecerei instruções passo a passo sobre como instalar o Apache Spark em um cluster em dois Slave.

Apache Spark é uma estrutura de processamento de dados que pode executar rapidamente tarefas de processamento em conjuntos de dados muito grandes e também pode distribuir tarefas de processamento de dados em vários computadores, por conta própria ou em conjunto com outras ferramentas de computação distribuídas.
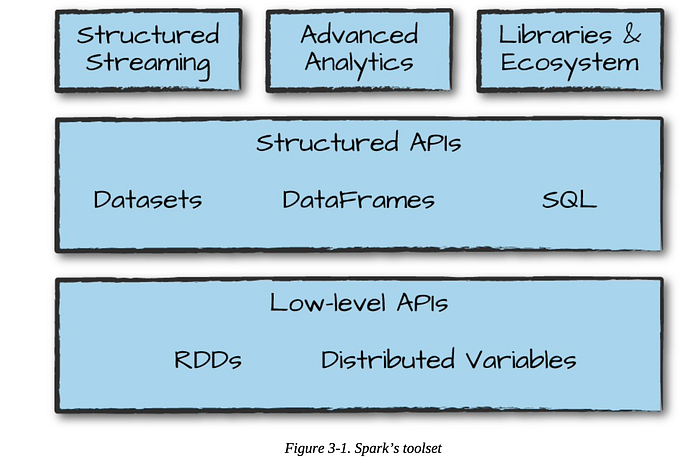
Arquitetura Spark
O Apache Spark segue uma arquitetura mestre / escravo com dois daemons principais e um gerenciador de cluster.
- Master Daemon — (Processo Master / Driver)
- Worker Daemon — (processo escravo)
- Gerenciador de clusters

Um cluster de faísca tem um único mestre e qualquer número de escravos / trabalhadores. O driver e os executores executam seus processos Java individuais e os usuários podem executá-los no mesmo cluster spark horizontal ou em máquinas separadas.
Pré-requisitos:
- Ubuntu 18.04 instalado numa máquina virtual
1º Passo:
Configuração da rede..:


1º Passo:
Agora, para instalar o Java, precisamos fazer algumas coisas. Siga estes comandos e dê permissão quando necessário:
sudo apt-get install software_properties_common
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install openjdk-11-jdk


Para verificar se o java está instalado, execute o seguinte comando.
java -version2º Passo:
Agora vamos instalar o Scala. Use este comando:
sudo apt-get install scala
Para verificar se o Scala foi instalado corretamente e a versão, execute este comando:
scala -version
Como você pode ver, o Scala versão 2.11.12 agora está instalado em minha máquina.

3º Passo:
Vamos configurar o SSH, mas esta etapa é apenas no mestre, precisamos instalar o Open SSH Server-Client , use o comando:
sudo apt-get install openssh-server openssh-clientDigite “Y” e depois Enter para continuar o processo de instalação.

4º Passo:
Crie 2 clones da Máquina Virtual
Certifique-se de que a opção “Generate new MAC addresses for all network adapters” de rede esta selecionado. Além disso, escolha a opção “Full Clone”.


5º Passo:
Vamos alterar o hostname em cada máquina virtual. Abra o arquivo e digite o nome da máquina. Use este comando:
sudo nano /etc/hostname



6º Passo:
Agora vamos descobrir qual é o nosso endereço IP. Para fazer isso, basta digitar o comando:
ip addr
Podemos ver que o ip da maquina é 192.168.56.101
Então a nossa configuração vai ser
- master: 192.168.56.101
- slave1: 192.168.56.102
- slave2: 192.168.56.103
7º Passo:
Abra o ficheiro hosts no editor nano. O ficheiro está localizado no diretório /etc.
sudo nano /etc/hosts
Para guardar as alterações que você fez, pressione Ctrl + O, depois pressione Enter, para guardar com o mesmo nome. Para sair do editor de texto nano, pressione Ctrl + X.
Reinicie a máquina para a configuração ter efeito em todas as máquinas.
sudo reboot8º Passo:
Crie uma chave ssh com o comando abaixo:
ssh-keygen -t rsa -P ""
9º Passo:
Use o seguinte comando para tornar esta chave autorizada:
cat ~ / .ssh / id_rsa.pub >> ~ / .ssh / authorized_keysCopiamos a chave ssh para todos os utilizadores
ssh-copy-id user@master
ssh-copy-id user@slave1
ssh-copy-id user@slave2

10º Passo:
Vamos verificar se deu tudo certo, tente conectar nos escravos:
ssh slave1
ssh slave2

Como você pode ver tudo correu bem, para sair basta digitar o comando:
exit
11º Passo:
Agora vamos baixar a versão mais recente do Apache Spark.
NOTA: Tudo dentro desta etapa deve ser feito em todas as máquinas virtuais.
Use o seguinte comando:
wget http://www-us.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgzEsta é a versão mais recente no momento da redação deste artigo, ela pode ter mudado se você tentar mais tarde. De qualquer forma, acho que você ainda será bom usando este.

Extraia o arquivo Apache Spark que você acabou de baixar
Use o seguinte comando para extrair o arquivo Spark tar:
tar xvf spark-3.1.1-bin-hadoop2.7.tgz
Mover arquivos de software Apache Spark
Use o seguinte comando para mover os arquivos do software spark para o respectivo diretório ( /usr/local/bin ):
sudo mv spark-3.1.1-bin-hadoop2.7 /usr/local/spark
Configure o ambiente para Apache Spark
Edite o arquivo .bashrc usando este comando:
sudo nano ~/.bashrcAdicione a seguinte linha ao arquivo. Isso adiciona o local onde o arquivo do software spark está localizado à variável PATH.
export PATH = $PATH:/usr/local/spark/bin
Para guardar as alterações que você fez, pressione Ctrl + O, depois pressione Enter, para guardar com o mesmo nome. Para sair do editor de texto nano, pressione Ctrl + X.
Agora precisamos usar o seguinte comando para fornecer o arquivo ~ / .bashrc :
source ~/.bashrc
12º Passo:
Configuração master do Apache Spark (execute esta etapa apenas na máquina master)
Editar spark-env.sh
Mova para a pasta spark conf, crie uma cópia do modelo de spark-env.sh e renomeie-o.
cd /usr/local/spark/conf cp spark-env.sh.template spark-env.sh

13º Passo:
Agora edite o arquivo de configuração spark-env.sh.
$ sudo vim spark-env.shE adicione os seguintes parâmetros:
export SPARK_MASTER_HOST = '<MASTER-IP>' export JAVA_HOME = <Path_of_JAVA_installation>
14º Passo:
Adicionar Workers
Edite o arquivo de configuração em ( /usr/local/spark/conf).
sudo nano slaves
15º Passo:
Vamos tentar iniciar nosso Apache Spark Cluster, espero que esteja tudo bem!
Para iniciar o cluster Spark, execute o seguinte comando no master:
cd /usr/local/spark./sbin/start-all.sh

Não vou parar, mas caso você queira parar o cluster, este é o comando:
./sbin/stop-all.sh16º Passo:
Para verificar se os serviços foram iniciados usamos o comando:
jps
17º Passo:
Navegue na IU do Spark para saber sobre seu cluster. Para fazer isso, vá para o seu navegador e digite:
master:8080/
Como está demonstrado na imagem anterior verificamos que é possível ver os ip’s dos nossos workers, em que vemos o nosso slave 1, slave 2 e o nosso master. Que demonstra que estão os 3 a trabalhar em simultâneo.
18º Passo:
Usando o Spark shell com o comando:
spark-shell
Para sair de uma sessão Scala do Spark, você pode digitar o comando :q e de seguida Enter.
Navegue na IU do Spark . Para fazer isso, vá para o seu navegador e digite:
master:4040/
Se desligarmos o nosso slave2 e efetuarmos o start (como demonstrado anteriormente), no browser verificamos o seguinte.

Conclusão:
Com isto chegamos ao fim.
Espero que você tenha sucesso, e este artigo seja útil.
Qualquer dúvida fique à vontade para me perguntar.